Format: Textfile
The Textfile format is the simplest storage format of all and is the default for tables in Hadoop systems.
It is only plain text where the fields are stored separated by a delimiter and each register is separated by a line.
Within this format depending on the structure of the delimiters we can have CVS, TSV, JSON Records,…
This format is human-readable and interpretable by most tools.
The data in this format occupy a lot and are not efficient to consult.
This type does not support compression.
Format: Sequence file
The Sequence File format is the storage format provides a persistent data structure for binary key-value pairs.
It ends with the problematic of the TextFile format where the text can not have the delimiter characters.
It is usually used for data transfers between works of Map-Reduce, because they are easily divisible.
The compression types recommended in this format are:
- Snappy
- Gzip
- Deflate
- Bzip2
Format: Parquet
The parquet format is an open-source format for storage in columns for Hadoop.
It was created to be able to have a free format of compression and efficient coding.
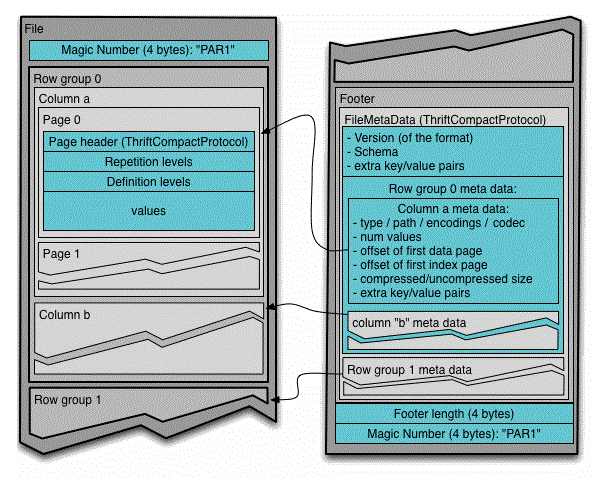
Structure of parquet files
The parquet format is made up of three pieces:
- Row group: is a set of rows in columnar format, with a size between 50Mb to 1GB.
- Column Chunk: Is the data of a column in a group. It can be read independently to improve readings.
- Page: It is where the data is finally stored should be large enough for the compression to be efficient.
In YARN environments, it is necessary to indicate how much memory a node can use to allocate resources with the parameter.
The compression types recommended in this format are:
- Snappy (default)
- Gzip
Source: Official website
Format: Avro
The parquet format is an open-source format used for data serialization.
This format is the result of the Apache Avro project, which is a compression system designed for data serialization that provides complex data structures, with a binary, compact and fast format.
The fundamental basis of the format are the schematics. Whenever you read a format. Avro is present the schema with which they have been written, this allows to increase the performance when writing the data, making the serialization fast and viable in space.
Avro schemas are defined in JSON to facilitate deployment with programming languages.
Also indicate that it supports evolution of schemas.
The compression types recommended in this format are:
- Snappy
- Gzip
- Deflate
- Bzip2
Format: ORC (optimized Row columnar)
The ORC format is a format that stores collections of rows in a file and within the collection in which row data is stored in a column format. This allows the parallel process of row collections in a cluster.
The format uses type-specific encoders for each column and divides the file into large bands.
The Bands use indexes that allow big SQL readers to jump large sets of rows that do not meet the filter condition.
Also highlight that ORC is a columnar format autodescriptive and untyped, designed to load jobs in Hadoop.
The compression types recommended in this format are:
- Zlib (the default value)




0 Comments