Descargar entorno de trabajo
Descargar la última versión de la máquina virtual CentOS (se utilizó la 6.7) y ejecutarla con virtualBox.
Iniciar la máquina virtual con el usuario hadoop (sino existe crearlo)
useradd hadoop passwd hadoop
Instalación de máquina Virtual Java
Descargar la máquina virtual de java
Abrir un terminal con usuario root:
su - cd /home/hadoop/Descargas
Instalar la máquina virtual de java
rpm -ivh jdk-8u191-linux-x64.rpm
Si disponemos de varias versiones de java podemos verificar que la que acabamos de instalar esta activa con:
alternatives --config java
Instalación de Hadoop
Descargar la última versión de hadoop de la web o bien descargarla mediante wget
wget http://apache.rediris.es/hadoop/common/hadoop-3.1.1/hadoop-3.1.1.tar.gz
Instalar el paquete de hadoop
tar xvf hadoop-3.1.1.tar.gz
Mover el directorio generado a /opt
mv hadoop-3.1.1 /opt
Comprobamos que existen ficheros en el directorio
ls -l /opt/hadoop
Cambiar los permisos recursivamente a hadoop
chown -R hadoop:hadoop hadoop-3.1.1
Comprobar que los permisos se ha modificado correctamente
ls -la
Configurar las variables de entorno
Configurar las variables de entorno para el usuario «hadoop»
su hadoop
Nota: Sino existe usuario crearle
useradd hadoop passwd hadoop
Incluir las variables de entorno en el fichero «/home/hadoop/.bashrc»
gedit /home/hadoop/.bashrc
Nota: Las variables a incluir son:
export JAVA_HOME=/usr/java/jdk1.8.0_191-amd64 export HADOOP_HOME=/opt/hadoop-3.1.1 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
Refrescar los cambios en el fichero
cd /home/hadoop/ . ./.bashrc
Comprobar que todo es correcto
hadoop -h
Configurar SSH
Vamos a configurar primero la IP y después los puertos SSH de hadoop.
Entramos con root y vemos la ip que tenemos:
su - ifconfig
Sacamos el nombre de la máquina con hostname o uname -a y nos devuelve nodo1.
hostname
Una vez que tenemos la ip y el nombre de la máquina se lo grabamos en hosts
gedit /etc/hosts
Ahí metemos la ip que nos ha dado la red un tabulador y el nombre de la maquina.
Comprobamos que es correcto con un ping y vemos que recibimos paquetes.
ping nodo1
Entramos con nuestro usuario HADOOP
su hadoop cd nos situamos en el raíz
Vamos al directorio por defecto de nuestro hadoop y generamos la clave SSH
cd /home/hadoop ssh-keygen
Pulsamos tres veces enter y va a generar la clave publica y privada.
Comprobamos que se han generado la clave ssh con:
ls -la cd .ssh
Vemos como ha generado varios ficheros, la clave publica es la que se va a ir pasando de un nodo a otro. podemos verlo con un cat id_rsa.pub, siempre tendremos en los nodos el usuario y de donde venimos.
Ahora copiamos el fichero y le nombramos authorized_keys (esto solo se hace para la máquina maestra).
cp id_rsa.pub authorized_keys.
Esto lo tenemos que ir haciendo a medida que vayamos creciendo en nodos.
nos vamos al directorio por defecto y hacemos
ssh nodo1
¡Lo normal es que no nos pida ninguna contraseña!
Finalmente salimos de ssh
exit
Instalación pseudo-distribuida
Ahora necesitamos configurar un par de ficheros: core_site.xml (fichero de configuración principal) y hdfs_site.xml (fichero de configuración del sistema).
Configurar el fichero core_site.xml
cd /opt/hadoop-3.1.1/etc/hadoop/
gedit core_site.xml
Pueden existir varios sistemas de ficheros con los que puede trabajar hadoop ,pero le configuramos el sistema de ficheros hdfs y de la siguiente manera:
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://nodo1:9000</value> </property> </configuration>
Configurar el fichero hdfs_site.xml
gedit hdfs_site.xml
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/datos/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/datos/datanode</value> </property> </configuration>
Si tenemos más de un nodo el valor de replication será 3 ( tres es un valor suficiente ), en este caso es 1 porque tenemos un nodo (ya que esta prueba es sobre una máquina semi-distribuida).
HDFS trabaja con una maquina maestra (NameNODE) y X maquinas esclavas (DataNODE). Tenemos que referirnos a ellas y crear unos directorios para namenodes y datanodes. Estos directorios lo vamos a llamar /datos (no es obligatorio llamarles así,pero para esta configuración nos permitirá verlo más claro). En este caso tenemos una maquina distribuida (en la realidad tendremos varias maquinas reales), por tanto las maquinas esclavas no tendrán la propiedad de replication y las maestras si la tendrán mientras que las namenodes no tendrán la propiedad con la ruta a los datos.
Creación del directorio de datos
su - mkdir /datos mkdir /datos/namenode mkdir /datos/datanode
necesitamos dar permisos al usuario hadoop como hicimos anteriormente.
chown -R hadoop:hadoop datos
Formateamos el sistema de ficheros que acabamos de crear
su hadoop hadoop namenode -format
Inicio del servicio HDFS
Ahora ejecutamos la instrucción para formatear y levantamos el sistema de ficheros con
start-dfs.sh
y ya estaría operativo el sistema de ficheros. Para comprobarlo debemos ver los procesos java que están corriendo en la máquina
jps
3696 SecondaryNameNode 3508 DataNode 6406 Jps 3401 NameNode 6364 JobHistoryServer
También puedes comprobar que el sistema está levantado accediendo desde el navegador a la url
https://nodo1:9870 (para hadoop 3 o superior);
Nota: Para hadoop v.2 la url es https://nodo1:50070
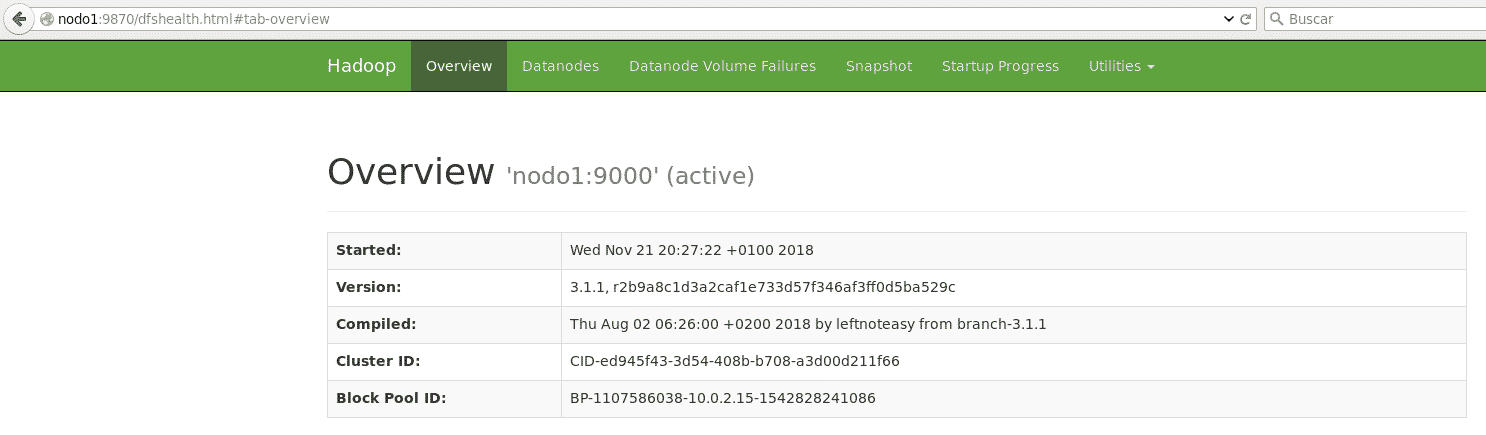
hadoop hdfs pantalla inicial
Configurar YARN para entorno Pseudo-Distribuido
Configurar el fichero mapred-site.xml
cd /opt/hadoop-3.1.1/etc/hadoop/ gedit mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
Nota: si solo existiese mapred-site.xml.template crear una copia con cp
Configurar el fichero yarn-site.xml
cd /opt/hadoop-3.1.1/etc/hadoop/ gedit yarn-site.xml
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>nodo1</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> </configuration>
Arrancar servicios YARN
Arrancar el servicio yarn
cd /opt/hadoop-3.1.1/sbin start-yarn.sh
Arrancamos el servicio que permite guardar el histórico de los Jobs lanzados
cd /opt/hadoop-3.1.1/sbin mr-jobhistory-daemon.sh start historyserver
Comprobamos que todo esta funcionado
jps
3696 SecondaryNameNode 5604 NodeManager 5492 ResourceManager 3508 DataNode 6406 Jps 3401 NameNode 6364 JobHistoryServer
Acceder al cluster
http://nodo1:8088/cluster
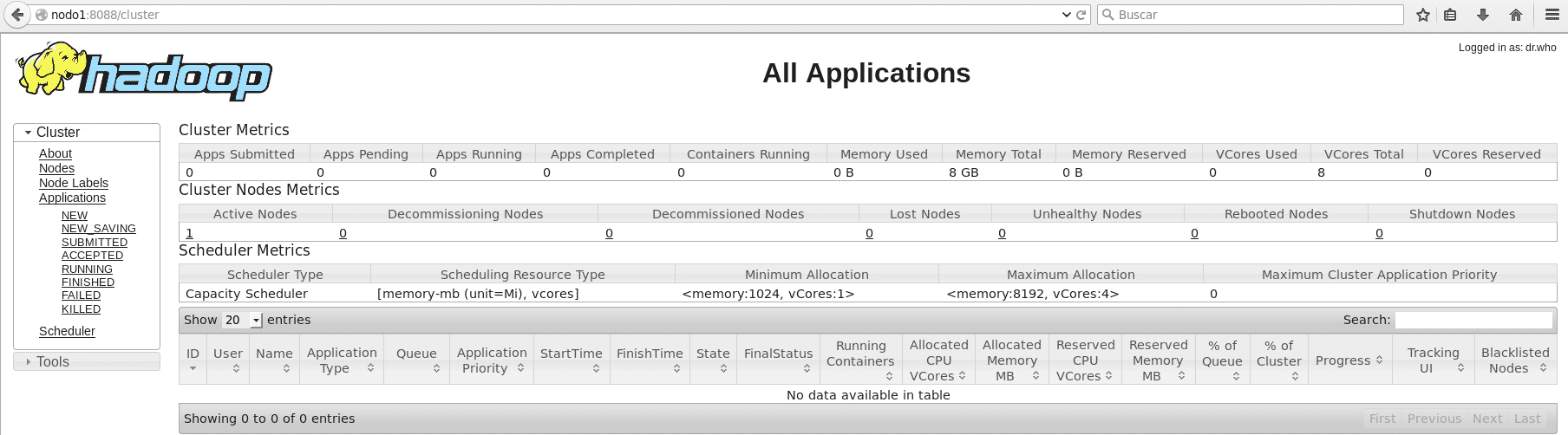
hadoop yarn pantalla inicial




Inútil