Uso: Determina la relación entre casos.
Variables: Métricas y no métricas.
Descripción: Permite clasificar una población en un número determinado de grupos, en base a semejanzas y discrepancias de los perfiles existentes entre los diferentes elementos de la población.
En los métodos jerárquicos los individuos no se particionan en clúster de una sola vez, sino que se van haciendo particiones sucesivas a por distintos niveles de agregación.
Normalmente estos métodos jerárquicos suelen ser ascendentes, es decir que sucesivamente van fusionando grupos desde el elemento individual hacia arriba.
Establecer una clasificación jerárquica supone poder realizar una serie de particiones del conjunto.
W = { i1 , i2 , …,iN } ; de forma que existan particiones a distintos niveles que vayan agregando (o desagregando, si se trata de un método divisivo) a las particiones de los niveles inferiores .
La representación de la jerarquía de clúster se representa por medio de un “dendograma”, en el que las sucesivas fusiones de las ramas a los distintos niveles nos informan de las sucesivas fusiones de los grupos en grupos de superior nivel (mayor tamaño, menor homogeneidad) sucesivamente:
Ejemplo en R: Clasificar flores atendiendo a sus características físicas de altura y anchura de sus pétalos y sépalos.
# Carga de datos inicial, tipos de flores con diferentes caracteristicas data(iris) datos <- iris View(datos) # Estandarización de los datos de las variables usadas en el estudio datos[,1:4] <- scale(datos[,1:4]) View(datos) # Nos quedamos todas las variables excepto la variable dependiente # Matriz de distancias distancias <- dist(datos[,1:4]) # Agrupamientos agrupamiento <- hclust(distancias) # Creación de k grupos (grupos <- cutree(agrupamiento, k=3)) # Visualización del arbol del cluster plot(agrupamiento,hang = -1,cex=0.7,labels = datos[,5], main= "Cluster sobre tipos de flor") # Visualización de los grupos formados por el cluster rect.hclust(agrupamiento, k=3, border="red")
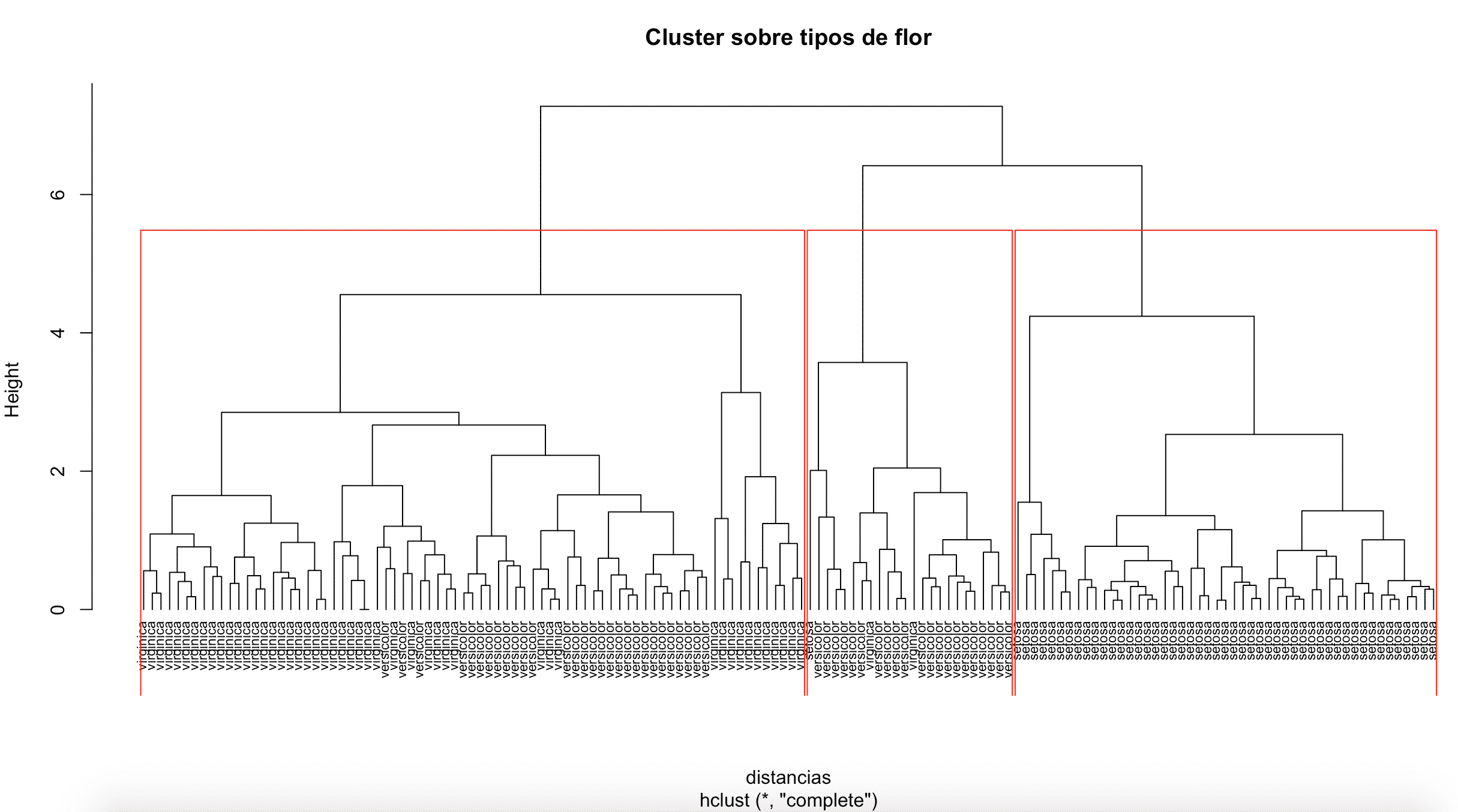
Cluster jerarquico – dendograma por tipo de flor




Me podrías explicar
plot(agrupamiento,hang = -1,cex=0.7,labels = datos[,5], main= «Cluster sobre tipos de flor»)
las variables hang= -1
Cex=0.7 ahh que se refiere
Buenas noches, para preguntar como hago un análisis de conglomerados para datos binarios?
Buenas tardes, me pudiera explicar luego de hacer los cortes, por ejemplo 4,6 u 8 cortes, cuál sería el mejor ?
Como corrijo es te error :Error in plot.new() : figure margins too large