La clasificación automática del sonido es un área de investigación en crecimiento con numerosas aplicaciones en el mundo real. Existe una gran cantidad de investigaciones en campos de audio relacionados con el habla y la música, aunque no existe tanta investigación en la clasificación de los sonidos ambientales.
Las posibles investigaciones de la clasificación de sonido ambientales, van dirigidas a poder dar respuesta a aplicaciones de tipo:
- Indización y recuperación multimedia basada en contenido.
- Ayudar a las personas sordas en sus actividades diarias.
- Casos de uso inteligente en el hogar, como capacidades de seguridad de 360 grados.
- Usos industriales como el mantenimiento predictivo.
- Uso en ámbito educativo, como control en las guarderías.
Planteamiento del problema
Se plantea desarrollar un clasificador de sonidos ambientales utilizando técnicas de aprendizaje profundo, centrándose particularmente en la identificación de sonidos urbanos particulares.
Para realizar el clasificador, se parte de un conjunto de datos con sonidos ambiente precategorizados.
Dataset
El conjunto de datos utilizados, es el conjunto de datos UrbanSound8K, que podeis descargar de la web Weebly
Este conjunto de datos contiene 8732 sonidos de menos de 4 segundos y se clasifican en las 10 clases siguientes:
• Air Conditioner
• Car Horn
• Children Playing
• Dog bark
• Drilling
• Engine Idling
• Gun Shot
• Jackhammer
• Siren
• Street Music
Los extractos de sonido son archivos de audio digital en formato .wav. Las ondas de sonido se digitalizan al muestrearlas a intervalos discretos conocidos como la frecuencia de muestreo (típicamente 44,1 kHz para muestras de audio de calidad de CD que se toman 44.100 veces por segundo).
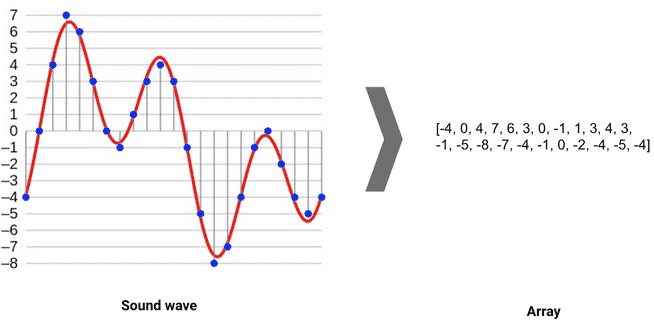
La imagen anterior muestra cómo se toma un extracto de sonido de una forma de onda y se convierte en una matriz unidimensional o vector de valores de amplitud.
Prerrequisitos e Instalación de librerías necesarias
Version de Python 3.6
pip install pandas
pip install librosa
pip install matplotlib
pip install keras
pip install numba==0.43.0 # Forzar la versión
# pip install llvmlite==0.32.1 # Solo si de problemasExploración de datos
Si realizamos simplemente una inspección visual, vemos que podemos distinguir algunas de las clases, aunque tenemos enormes dificultades en sonidos que son repetitivos como por ejemplo el Aire acondicionado o el ralentí del motor.
# Load imports
import IPython.display as ipd
import librosa
import librosa.display
import matplotlib.pyplot as plt# Class: Air Conditioner
filename = '/audio/fold1/100263-2-0-117.wav'
plt.figure(figsize=(12,4))
data,sample_rate = librosa.load(filename)
_ = librosa.display.waveplot(data,sr=sample_rate)
ipd.Audio(filename)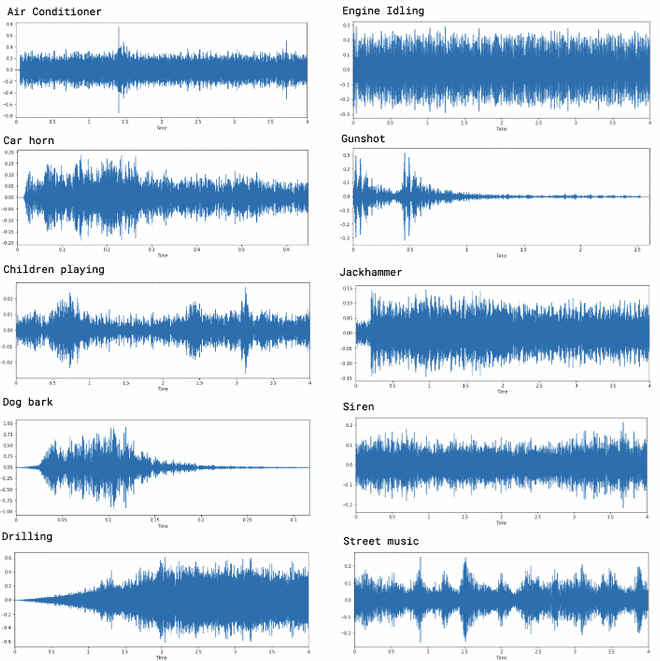
En un análisis más profundo, realizaremos la extracción de cada una de las propiedades de los archivos de audio:
- Número de canales de audio.
- Frecuencia de muestreo.
- Profundidad de bits.
Estructura de ficheros wave
La estructura de los ficheros wave se organiza de la siguiente manera:
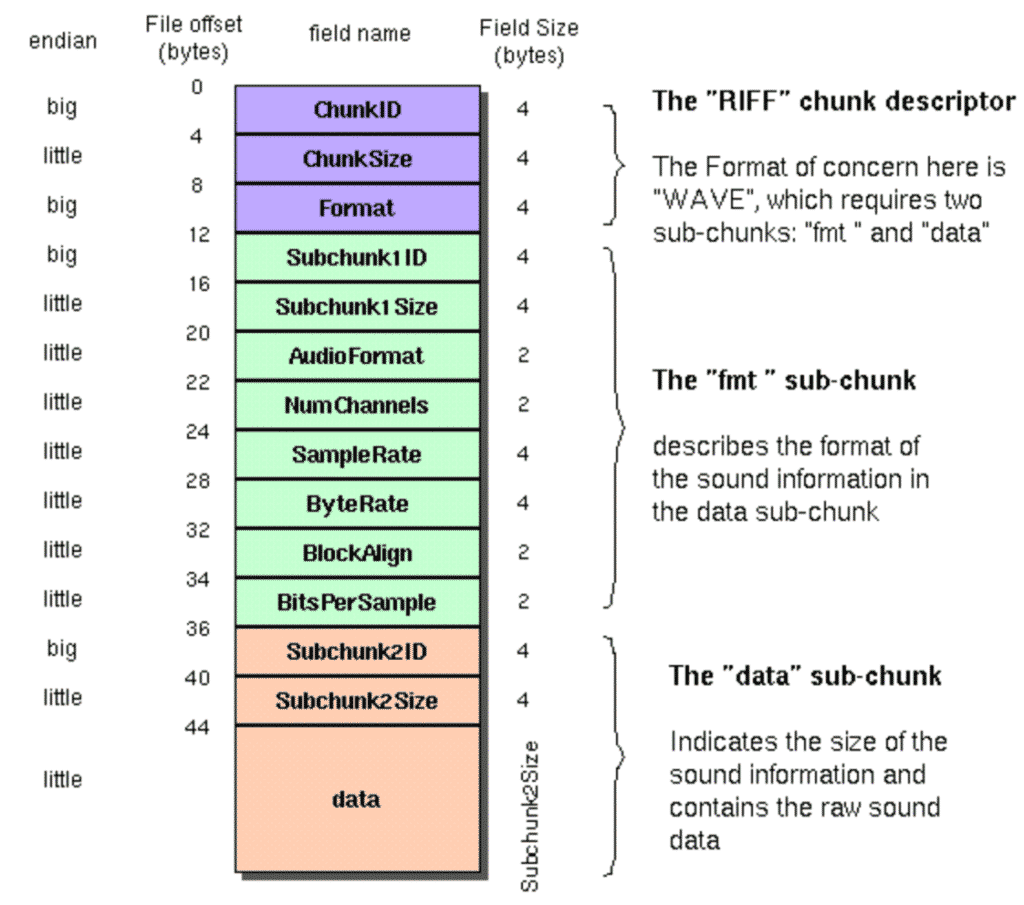
Para extraer las 3 propiedades concretas que necesitamos de los ficheros wave, utilizaremos el siguiente código:
import struct
class WavFileHelper():
def read_file_properties(self, filename):
wave_file = open(filename, "rb")
riff = wave_file.read(12)
fmt = wave_file.read(36)
num_channels_string = fmt[10:12]
num_channels = struct.unpack('<H', num_channels_string)[0]
sample_rate_string = fmt[12:16]
sample_rate = struct.unpack("<I", sample_rate_string)[0]
bit_depth_string = fmt[22:24]
bit_depth = struct.unpack("<H", bit_depth_string)[0]
return (num_channels, sample_rate, bit_depth)
wavfilehelper = WavFileHelper()
data = wavfilehelper.read_file_properties('/Users/diegocalvo/Desktop/audio/fold5/100032-3-0-0.wav')
print(data)# (2, 44100, 16)# Set the path to the full UrbanSound dataset
fulldatasetpath = 'audio/'
import pandas as pd
# Set the path to metadata.
metadata = pd.read_csv('audio/UrbanSound8K.csv')
metadata.head(10)
print(metadata.classID.value_counts())Composición de los datos a explorar
# Load various imports
import pandas as pd
import os
import librosa
import librosa.display
wavfilehelper = WavFileHelper()
audiodata = []
for index, row in metadata.iterrows():
file_name = os.path.join(os.path.abspath(fulldatasetpath),'fold'+str(row["fold"])+'/',str(row["slice_file_name"]))
data = wavfilehelper.read_file_properties(file_name)
audiodata.append(data)
# Convert into a Panda dataframe
audiodf = pd.DataFrame(audiodata, columns=['num_channels','sample_rate','bit_depth'])
Después de calcular las propiedades vamos a analizarlas individualmente:
Canales de audio: Vemos que existen canales en «mono» u otros en «estereo», por ello la siguiente variable nos muestra dos salidas diferentes.
print(audiodf.num_channels.value_counts(normalize=True))Frecuencia de muestreo: Vemos que existe una amplia gama de frecuencias de muestreo y esto hace que los datos no sean comparables.
print(audiodf.sample_rate.value_counts(normalize=True))Profundidad de bits: También podemos ver que existen diferentes profundidades dependiendo de la muestra.
print(audiodf.bit_depth.value_counts(normalize=True))Al realizar el análisis podemos ver que el conjunto de datos tiene una gama de propiedades de audio variables que no permiten comparar de forma directa unas con otras, por ello necesitamos estandarizar antes de que podamos usarlo para entrenar nuestro modelo.
Estandarización de datos
Fijar una ventana deslizante con duración de 2 segundos y una superposición de 1 Segundo.
Fijar un número de bandas de frecuencia, si el número es demasiado corto perdemos resolución y si es demasiado alto tendremos muchas bandas vacías.
Extraer características
Posteriormente extraemos las características propias de cada imagen que nos van a permitir entrenar el modelo.
Para ello, vamos a crear una representación visual de cada una de las muestras de audio que nos permitirá identificar características para la clasificación, utilizando las mismas técnicas utilizadas para clasificar imágenes.
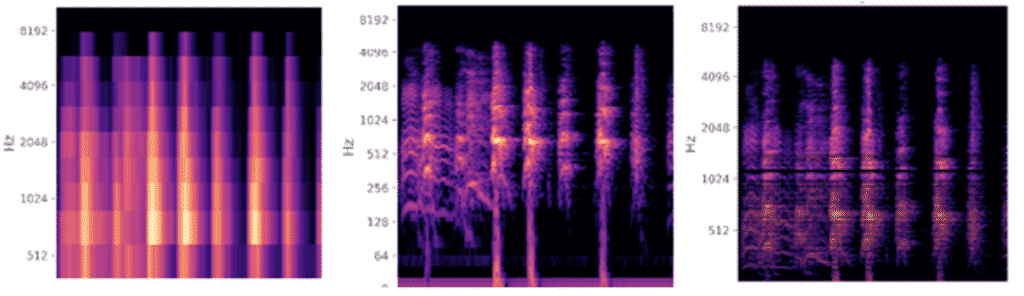
Los espectrogramas son una técnica útil para visualizar el espectro de frecuencias de un sonido y cómo varían durante un período de tiempo muy corto. Utilizaremos una técnica similar conocida como Mel-Frequency Cepstral Coefficients (MFCC).
La principal diferencia es que un espectrograma usa una escala de frecuencia lineal espaciada (por lo que cada intervalo de frecuencia está espaciado un número igual de Hertz), mientras que un MFCC usa una escala de frecuencia espaciada cuasi-logarítmica, que es más similar a cómo el sistema auditivo humano procesa sonidos.
La imagen a continuación compara tres representaciones visuales diferentes de una onda de sonido, la primera es la representación en el dominio del tiempo, comparando la amplitud en el tiempo. La siguiente es un espectrograma que muestra la energía en diferentes bandas de frecuencia que cambian con el tiempo, y finalmente, un MFCC que podemos ver que es muy similar a un espectrograma pero con detalles más distinguibles.
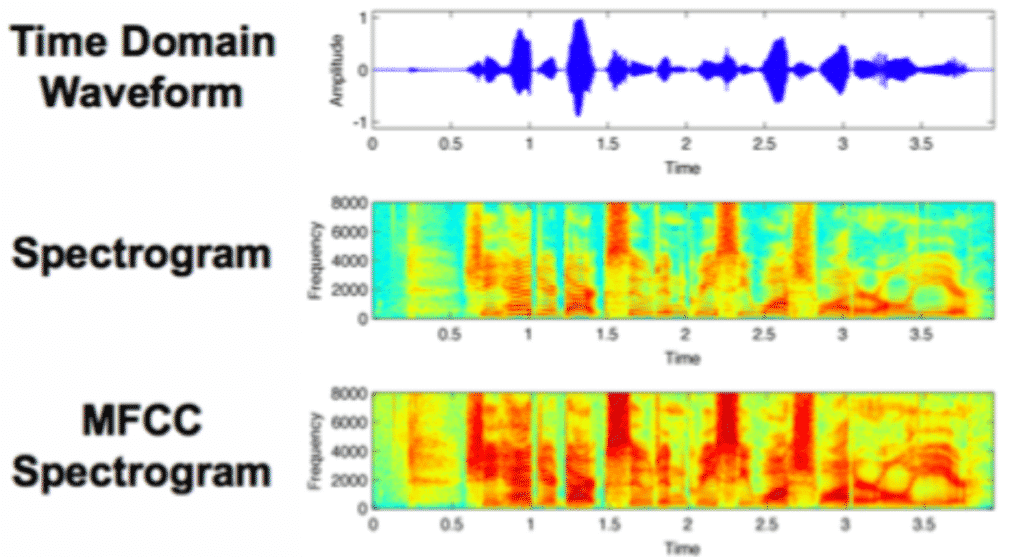
Para cada archivo de audio en el conjunto de datos, extraeremos un MFCC (lo que significa que tenemos una representación de imagen para cada muestra de audio) y lo almacenaremos en un Panda Dataframe junto con su etiqueta de clasificación. Para esto, utilizaremos la función mfcc() de Librosa, que genera un MFCC a partir de datos de audio de series temporales.
import numpy as np
def extract_features(file_name):
try:
audio, sample_rate = librosa.load(file_name, res_type='kaiser_fast')
mfccs = librosa.feature.mfcc(y=audio, sr=sample_rate, n_mfcc=40)
mfccsscaled = np.mean(mfccs.T,axis=0)
except Exception as e:
print("Error encountered while parsing file: ", file_name)
return None
return mfccsscaled# Load various imports
import pandas as pd
import os
import librosa
features = []
# Iterate through each sound file and extract the features
for index, row in metadata.iterrows():
file_name = os.path.join(os.path.abspath(fulldatasetpath),'fold'+str(row["fold"])+'/',str(row["slice_file_name"]))
class_label = row["classID"]
data = extract_features(file_name)
features.append([data, class_label])
# Convert into a Panda dataframe
featuresdf = pd.DataFrame(features, columns=['feature','class_label'])
print('Finished feature extraction from ', len(featuresdf), ' files') features = featuresdf.loc[1]
print( list(features) )Convertir los datos y etiquetas
Para transformar los datos categóricos a numéricos usaremos «LabelEncoder» y así conseguiremos que el modelo sea capaz de entenderlos.
from sklearn.preprocessing import LabelEncoder
from keras.utils import to_categorical
# Convert features and corresponding classification labels into numpy arrays
X = np.array(featuresdf.feature.tolist())
y = np.array(featuresdf.class_label.tolist())
# Encode the classification labels
le = LabelEncoder()
yy = to_categorical(le.fit_transform(y)) print(X)
print(y)
print(yy)Dividir los datos en entrenamiento y test
Dividimos el conjunto de datos en dos bloques (80% y 20%) y de ellos sacamos valores de X y de Y
# split the dataset
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(X, yy, test_size=0.2, random_state = 42)x_train.shapex_test.shapeConstruir el modelo
Construimos una red neuronal mediante un perceptrón multicapa (MLP) usando Keras y un backend de Tensorflow.
Se plantea un modelo secuencial para que podamos construir el modelo capa por capa.
Se plantea una arquitectura de modelo simple, compuesta por:
- Capa de entrada con 40 nodos, ya que la función MFCC de extracción de características nos devuelve un conjunto de datos de 1×40
- Capas ocultas de 256 nodos, estas capas tendrán una capa densa con una función de activación de tipo
ReLu, (se ha demostrado que esta función de activación funciona bien en redes neuronales). También destacar que aplicaremos un valor deDropoutdel 50% en nuestras dos primeras capas. Esto excluirá al azar los nodos de cada ciclo de actualización, lo que a su vez da como resultado una red que es capaz de responder mejor a la generalización y es menos probable que se produzca sobreajuste en los datos de entrenamiento. - Capa de salida de 10 nodos, que coinciden con el número de clasificaciones posibles. La activación es para nuestra capa de salida una función
softmax. Softmax hace que la salida sume 1, por lo que la salida puede interpretarse como probabilidades. El modelo hará su predicción según la opción que tenga la mayor probabilidad
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Convolution2D, MaxPooling2D
from keras.optimizers import Adam
from keras.utils import np_utils
from sklearn import metrics
num_labels = yy.shape[1]
filter_size = 2
# Construct model
model = Sequential()
model.add(Dense(256, input_shape=(40,)))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(256))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_labels))
model.add(Activation('softmax'))Compilar el modelo
Para compilar nuestro modelo, utilizaremos los siguientes tres parámetros:
- Función de pérdida: utilizaremos
categorical_crossentropy. Esta es la opción más común para la clasificación. Una puntuación más baja indica que el modelo está funcionando mejor. - Métricas: utilizaremos la métrica de
accuracyque nos permitirá ver la precisión en los datos de validación cuando entrenemos el modelo. - Optimizador: aquí usaremos
adam, que generalmente es un buen optimizador para muchos casos de uso.
# Compile the model
model.compile(loss='categorical_crossentropy', metrics=['accuracy'], optimizer='adam')
# Display model architecture summary
model.summary()
# Calculate pre-training accuracy
score = model.evaluate(x_test, y_test, verbose=0)
accuracy = 100*score[1]
print("Pre-training accuracy: %.4f%%" % accuracy)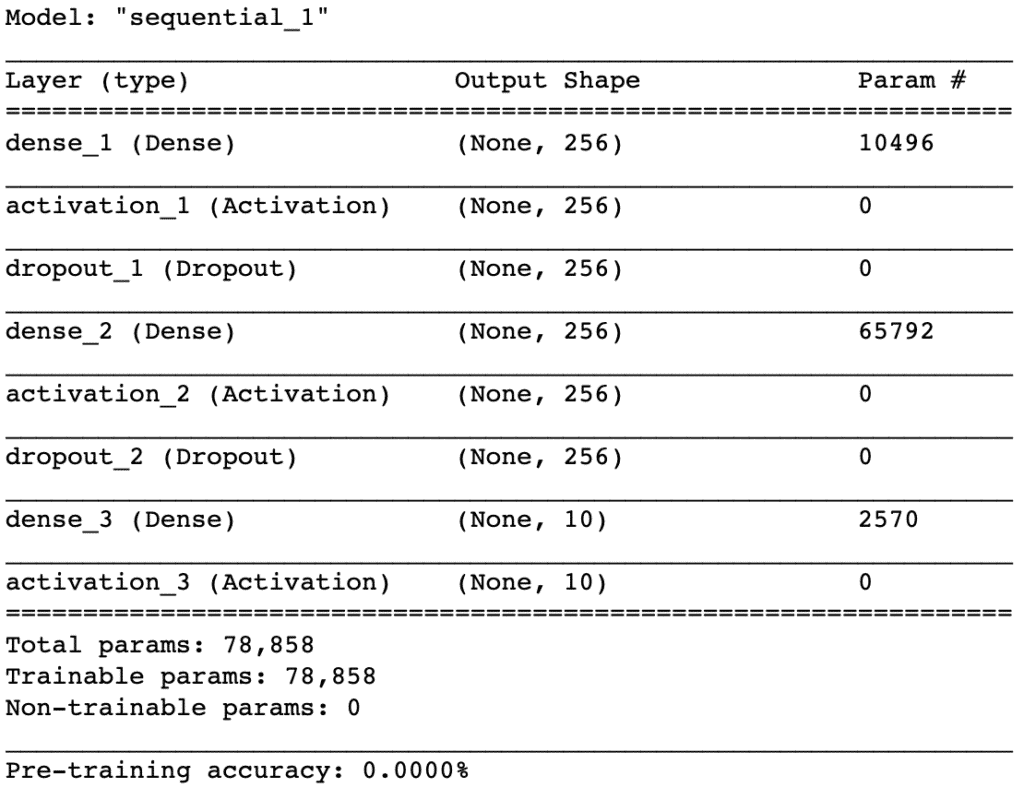
Entrenar el modelo
Se empieza probando con un número de épocas bajo y se prueba hasta ver donde alcanza un valor asintótico en el que por más que subamos las épocas no conseguimos que el modelo mejore significativamente.
Por otro lado, el tamaño del lote debe ser suficientemente bajo, ya que tener un tamaño de lote grande puede reducir la capacidad de generalización del modelo.
from keras.callbacks import ModelCheckpoint
from datetime import datetime
num_epochs = 100
num_batch_size = 32
checkpointer = ModelCheckpoint(filepath='saved_models/weights.best.basic_mlp.hdf5',
verbose=1, save_best_only=True)
start = datetime.now()
model.fit(x_train, y_train, batch_size=num_batch_size, epochs=num_epochs,
validation_data=(x_test, y_test), callbacks=[checkpointer], verbose=1)
duration = datetime.now() - start
print("Training completed in time: ", duration)Evaluar el modelo
Finalmente, para determinar la precisión del modelo generado, llamamos a la función evaluate y le pasamos los datos de test que hemos definido previamente.
# Evaluating the model on the testing set
score = model.evaluate(x_test, y_test, verbose=0)
print("Testing Accuracy: ", score[1])# Testing Accuracy: 1.0



Fascinante tu trabajo, muy claro y detallado, me parece genial poder ver tu investigación sobre el clasificador de sonidos ambientales, a diferencia del conjunto de datos Urbansound8K, ¿pudiste poner a prueba tu modelo haciendo uso de datos muestrados por ti, o otro conjunto de datos
?