Los almacenes de datos por columnas se caracterizan por el aumento de la localidad de los datos, esto es así porque los valores de una misma columna están próximos en el dispositivo de almacenamiento externo, gracias a ello se puede resolver de forma eficiente, dado que las operaciones de E/S de lectura de páginas que se desencadenan recuperan únicamente datos potencialmente útiles.
La localidad facilita la compresión de los datos ya se basa fundamentalmente en buscar repeticiones en una serie de datos (el conjunto de valores de cada una de las columnas de una tabla puede ser visto como una serie), que se representan de forma resumida.
Los valores representados son:
- Número de valores diferentes que toma la columna.
- Número de valores repetidos que existen para cada valor.
- Frecuencia de aparición de la columna en predicados de selección
- Tipo de datos asociado.
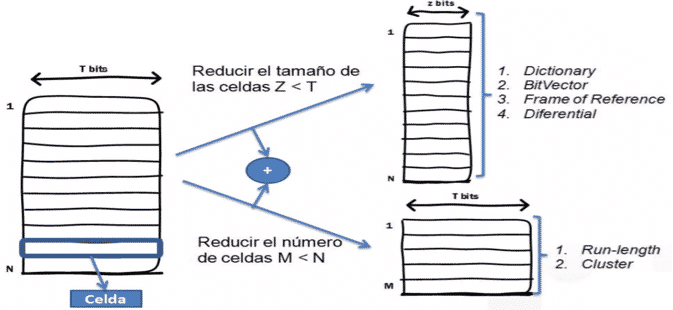
Tipos de algoritmos de compresión:
Fuente: Universidad Oberta de Cataluña
Reducen el número de valores (celdas)
Run-length encoding
- Reduce el número de celdas de una columna.
- Elimina valores repetidos.
- Reemplaza valores iguales que aparecen en celdas consecutivas por una tripleta de:
- Valor.
- Posición de inicio.
- Número de repeticiones.
Uso: Columnas ordenadas.

Cluster encoding
- Reduce el número de celdas de una columna.
- Elimina valores repetidos.
- Trabaja a nivel de bloque:
- Se distribuyen los valores de la columna en N bloques (clusters) de tamaño fijo.
- Si todos los valores del bloque son iguales se sustituye el valor sino se mantiene intacto.
Uso: Columnas ordenadas por clave secundaria

Reducen el tamaño de valores (celdas)
Diccionary encoding
- Crea un diccionario con todos los valores de la columna
- Sustituye los valores de la columna por referencias a su valor.
Uso: Columna de tipo string o tamaño considerable y puede combinarse con otros algoritmos.

Bit-vector encoding
- Permite representar múltiples valores para cada fila.
- Crea M vectores de bits de N posiciones.
- M valores que toman los datos.
- N longitud del vector a comprimir.
Uso: Columna con pocos valores posibles: sexo, categoría, … y puede combinarse con otros algoritmos.

Frame of reference encoding
- Coger un valor de referencia para todas las celdas
- Reescribir la columna restando el valor de la referencia.
- Los que se salen mucho de la media se tratan como valores atípicos, indicando infinito y marcando el valor sin comprimir.
Uso: Columna con poca variabilidad con respecto al valor medio.

Diferential encoding
- Necesita que la columna este ordenada
- Parecido a Frame of reference pero restableciendo el valor al salir de rango
Uso: Columna con poca variabilidad con respecto al valor medio y ordenados. Ejemplo fechas.

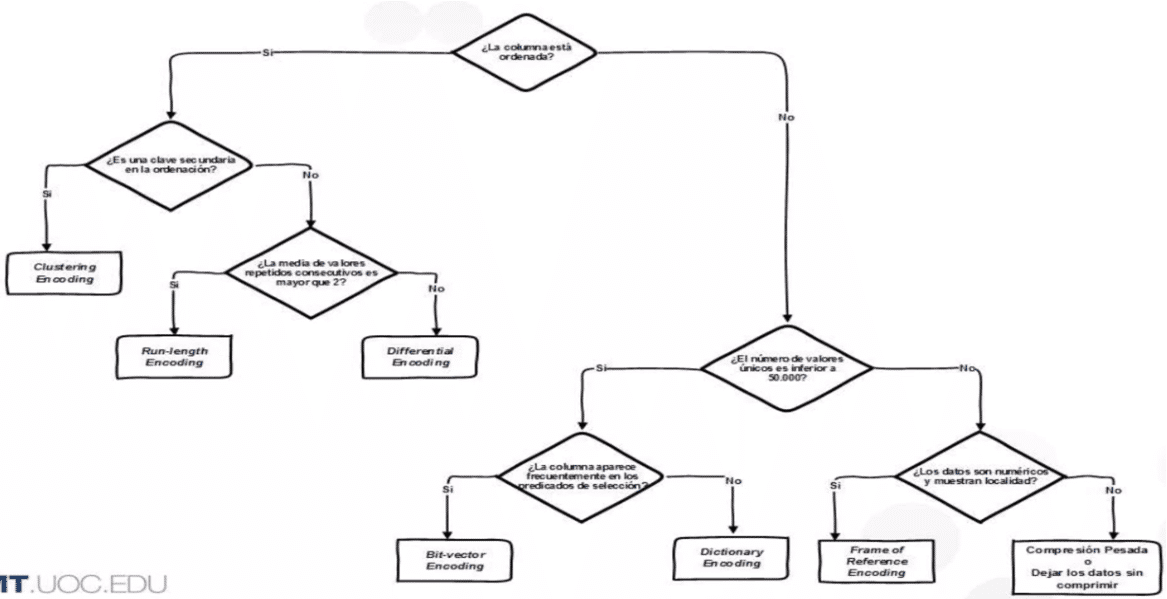
Elección del tipo de compresión:
Fuente: Universidad Oberta de cataluña
Adicionalmente, productos como Vertica/C-Store, Actian Vector/VectorWise o Amazon Redshift acostumbran a incorporar utilidades que ayudan a elegir los algoritmos de compresión,




0 comentarios