Ejemplo en Scala Spark de multiplicar por dos un vector
En este ejemplo se muestran los pasos a seguir para crear un proyecto spark en Scala y ejecutarlo como un trabajo en el sistema distribuido
Crear proyecto
Entrar en el entorno de desarrollo IntelliJ Idea y crear un nuevo proyecto Scala de tipo SBT
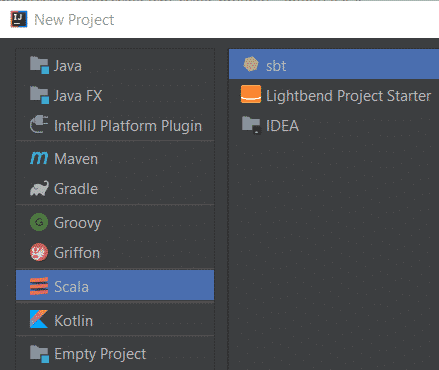
Configurar los parametros del proyecto, en los que hay que tener en cuenta que no soporta correctamente las ultimas versiones de Scala, por ello se recimienda poner la versión 2.10.6
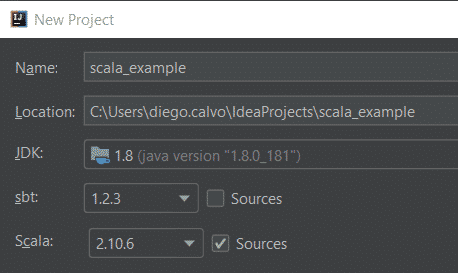
Configurar SBT
Modificar el fichero built.sbt
name := "scala_example" version := "0.1" scalaVersion := "2.10.6" libraryDependencies += "org.apache.spark" %% "spark-core" % "1.0.0"
Aceptar las autoimportaciones
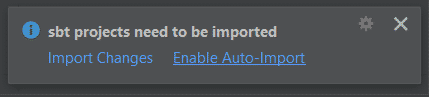
Definir la clase Scala principal
Crear el paquete «com.example» dentro de la carpeta src/main/scala y crear el fichero que contenga la clase principal (boton derecho crear scala class > object)
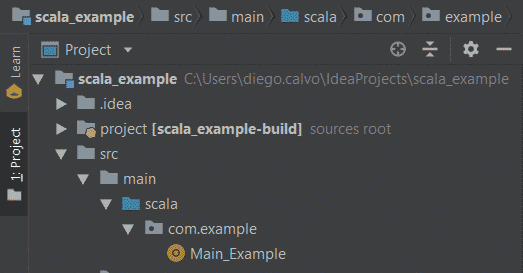
Una vez creado el objeto Main_Example modificar su contenido por el siguiente:
package com.example
import org.apache.spark.{SparkConf, SparkContext}
object Main_Example {
def main(args: Array[String])
{
println("Hola Mundo.")
val conf = new SparkConf().setAppName("DiegoWeb").setMaster("local[2]").set("spark.executor.memory", "1g")
val sc = new SparkContext(conf)
val rdd1 = sc.parallelize(List(1, 2, 3, 4, 5, 6, 7, 8, 9))
val rdd2 = rdd1.map(_ * 2)
rdd2.collect().foreach(println)
println("Se ha impreso la lista (1, 2, 3, 4, 5, 6, 7, 8, 9) por 2")
}
}
Ejecución del programa
Basta con pichar el boton de arranque (>) que sale al lado del objeto principal «Main_Example», para poder obtener el siguiente resultado:
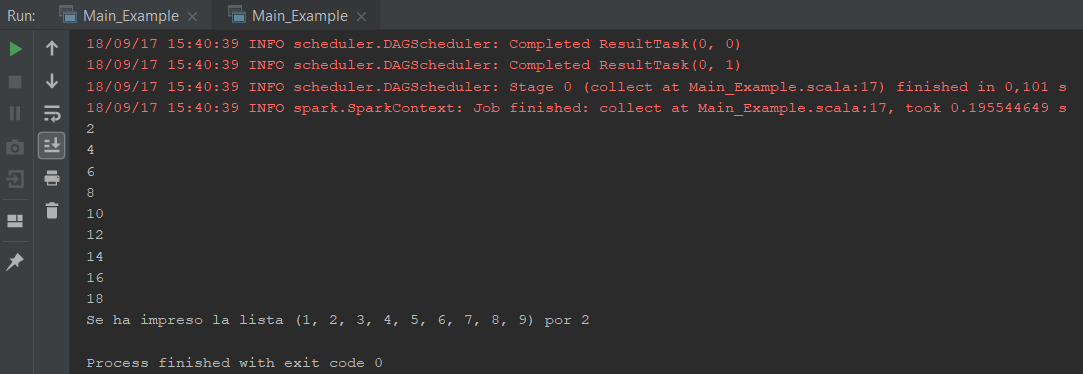
Crear el .JAR
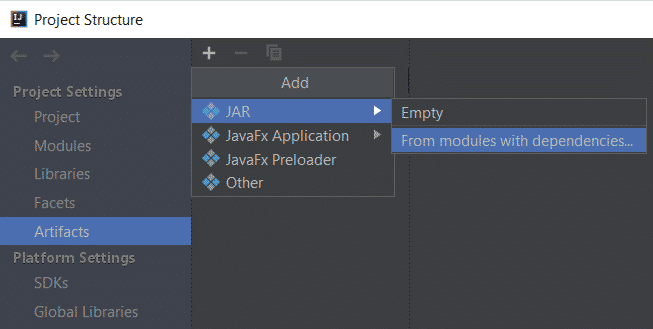
Debemos de ir a la estructura del proyecto File > Project Structure
Una vez alli de crear un Artefacto JAR en el que se incluyan las dependencias
Para construir el .JAR basta con construir el artefacto (Built > Built Artifacts)
Para probar el .jar generado simplemente boton derecho sobre el jar generado en out/artifacts/scala_example_jar/scala_example.jar
Ejecución distribuida del script
Para ejecutar de forma distribuida el script en Scala dentro de un entorno distribuido como puede ser Hortonworks, se debe ejecutar desde el shell la siguiente instrucción:
spark-submit --master local[2] \ --executor-memory 1g \ --name hola_mundo\ --conf "spark.app.id=hola_mundo" \ --class com.examples.MainExample \ out/artifacts/scala_example_jar/scala_example.jar
Nota: “\” se ponen para indicar al interprete del shell que la instrucción continua en la siguiente linea.
Fuente: Documentación oficial sobre comandos de spark-submit




hola, yo he seguido todos los pasos y no hay manera de importar paquetes como:
import org.apache.spark.{SparkConf, SparkContext}
Se quedan en gris y es como si no estuviera escribiendo nada.