from pyspark.ml import Pipeline
from pyspark.ml.feature import VectorAssembler
# Definir el 'df' Spark a utilizar
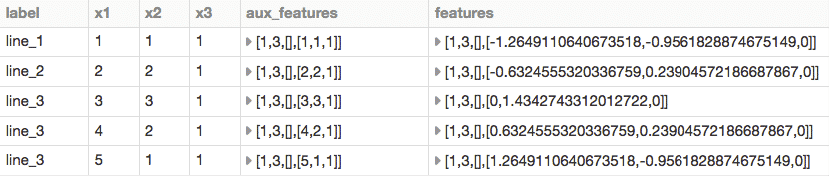
df = spark.createDataFrame([
('line_1', 1, 1, 1),
('line_2', 2, 2, 1),
('line_3', 3, 3, 1),
('line_3', 4, 2, 1),
('line_3', 5, 1, 1),
], ("label", "x1", "x2", "x3"))
# Definir un ensamblador de las columnas 'x1', 'x2' y 'x3' que toma como salida 'aux_features'
assembler = VectorAssembler(inputCols=["x1", "x2","x3"], outputCol="aux_features")
# Definir el método que estandariza la entrada 'aux_features', mostrando la salida en 'features'
standarization = StandardScaler(inputCol="aux_features", outputCol="features", withStd=True, withMean=True)
# Crear la tuberia
pipelineResult = Pipeline()
# Definir las etapas de las que está compuesta la tuberia
pipelineResult.setStages([assembler, standarization])
# Modelo de ajuste de la tuberia con los datos 'df' de entrada
modelResult = pipelineResult.fit(df)
#Realiza la transformación de los datos utilizando el modelo
result_df = modelResult.transform(df)
# Muestra los resultados
display(result_df)





0 comentarios